publications
My publications by categories in reversed chronological order.
2026
- ICLR 2026
 Human-Object Interaction via Automatically Designed VLM-Guided Motion PolicyZekai Deng, Ye Shi, Kaiyang Ji, and 3 more authorsIn The Fourteenth International Conference on Learning Representations (ICLR), 2026
Human-Object Interaction via Automatically Designed VLM-Guided Motion PolicyZekai Deng, Ye Shi, Kaiyang Ji, and 3 more authorsIn The Fourteenth International Conference on Learning Representations (ICLR), 2026Human-object interaction (HOI) synthesis is crucial for applications in animation, simulation, and robotics. However, existing approaches either rely on expensive motion capture data or require manual reward engineering, limiting their scalability and generalizability. In this work, we introduce the first unified physics-based HOI framework that leverages Vision-Language Models (VLMs) to enable longhorizon interactions with diverse object types—including static, dynamic, and articulated objects. We introduce VLM-Guided Relative Movement Dynamics (RMD), a fine-grained spatio-temporal bipartite representation that automatically constructs goal states and reward functions for reinforcement learning. By encoding structured relationships between human and object parts, RMD enables VLMs to generate semantically grounded, interaction-aware motion guidance without manual reward tuning. To support our methodology, we present Interplay, a novel dataset with thousands of long-horizon static and dynamic interaction plans. Extensive experiments demonstrate that our framework outperforms existing methods in synthesizing natural, human-like motions across both simple single-task and complex multi-task scenarios.
@inproceedings{deng2025human, title = {Human-Object Interaction via Automatically Designed VLM-Guided Motion Policy}, author = {Deng, Zekai and Shi, Ye and Ji, Kaiyang and Xu, Lan and Huang, Shaoli and Wang, Jingya}, booktitle = {The Fourteenth International Conference on Learning Representations (ICLR)}, year = {2026}, }
2025
- preprint
 Commanding Humanoid by Free-form Language: A Large Language Action Model with Unified Motion VocabularyZhirui Liu*, Kaiyang Ji*, Ke Yang, and 3 more authorsarXiv preprint arXiv:2511.22963, 2025
Commanding Humanoid by Free-form Language: A Large Language Action Model with Unified Motion VocabularyZhirui Liu*, Kaiyang Ji*, Ke Yang, and 3 more authorsarXiv preprint arXiv:2511.22963, 2025Enabling humanoid robots to follow free-form language commands is critical for seamless human-robot interaction, collaborative task execution, and general-purpose embodied intelligence. While recent advances have improved low-level humanoid locomotion and robot manipulation, language-conditioned whole-body control remains a significant challenge. Existing methods are often limited to simple instructions and sacrifice either motion diversity or physical plausibility. To address this, we introduce HumanoidLLA, a Large Language Action Model that maps expressive language commands to physically executable wholebody actions for humanoid robots. Our approach integrates three core components: a unified motion vocabulary that aligns human and humanoid motion primitives into a shared discrete space; a vocabulary-directed controller distilled from a privileged policy to ensure physical feasibility; and a physics-informed fine-tuning stage using reinforcement learning with dynamics-aware rewards to enhance robustness and stability. Extensive evaluations in simulation and on a real-world Unitree G1 humanoid show that Humanoid-LLA delivers strong language generalization while maintaining high physical fidelity, outperforming existing language-conditioned controllers in motion naturalness, stability, and execution success rate.
@article{liu2025commanding, title = {Commanding Humanoid by Free-form Language: A Large Language Action Model with Unified Motion Vocabulary}, author = {Liu, Zhirui and Ji, Kaiyang and Yang, Ke and Yu, Jingyi and Shi, Ye and Wang, Jingya}, journal = {arXiv preprint arXiv:2511.22963}, year = {2025}, } - preprint
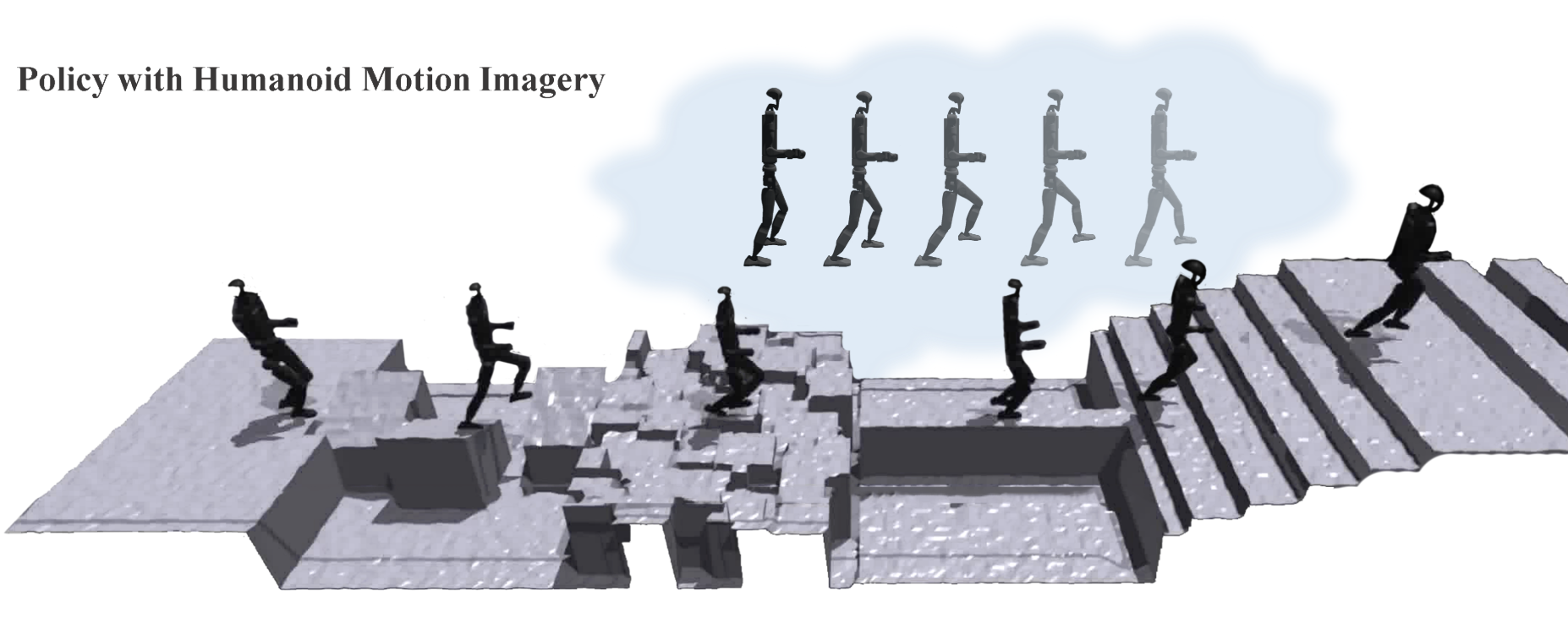 One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid LocomotionYahao Fan*, Tianxiang Gui*, Kaiyang Ji*, and 6 more authorsarXiv preprint arXiv:2505.18780, 2025
One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid LocomotionYahao Fan*, Tianxiang Gui*, Kaiyang Ji*, and 6 more authorsarXiv preprint arXiv:2505.18780, 2025Humanoid locomotion faces a critical scalability challenge: traditional reinforcement learning (RL) methods require task-specific rewards and struggle to leverage growing datasets, even as more training terrains are introduced. We propose DreamPolicy, a unified framework that enables a single policy to master diverse terrains and generalize zero-shot to unseen scenarios by systematically integrating offline data and diffusion-driven motion synthesis. At its core, DreamPolicy introduces Humanoid Motion Imagery (HMI) - future state predictions synthesized through an autoregressive terrain-aware diffusion planner curated by aggregating rollouts from specialized policies across various distinct terrains. Unlike human motion datasets requiring laborious retargeting, our data directly captures humanoid kinematics, enabling the diffusion planner to synthesize "dreamed" trajectories that encode terrain-specific physical constraints. These trajectories act as dynamic objectives for our HMI-conditioned policy, bypassing manual reward engineering and enabling cross-terrain generalization. Crucially, DreamPolicy addresses the scalability limitations of prior methods: while traditional RL fails to exploit growing datasets, our framework scales seamlessly with more offline data. As the dataset expands, the diffusion prior learns richer locomotion skills, which the policy leverages to master new terrains without retraining. Experiments demonstrate that DreamPolicy achieves an average of 90% success rates in training environments and an average of 20% higher success on unseen terrains than the prevalent method. It also generalizes to perturbed and composite scenarios where prior approaches collapse. By unifying offline data, diffusion-based trajectory synthesis, and policy optimization, DreamPolicy overcomes the "one task, one policy" bottleneck, establishing a paradigm for scalable, data-driven humanoid control.
@article{fan2025one, title = {One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid Locomotion}, author = {Fan, Yahao and Gui, Tianxiang and Ji, Kaiyang and Ding, Shutong and Zhang, Chixuan and Gu, Jiayuan and Yu, Jingyi and Wang, Jingya and Shi, Ye}, journal = {arXiv preprint arXiv:2505.18780}, year = {2025}, } - preprint
 DAG: Unleash the Potential of Diffusion Model for Open-Vocabulary 3D Affordance GroundingHanqing Wang*, Zhenhao Zhang*, Kaiyang Ji*, and 5 more authorsarXiv preprint arXiv:2508.01651, 2025
DAG: Unleash the Potential of Diffusion Model for Open-Vocabulary 3D Affordance GroundingHanqing Wang*, Zhenhao Zhang*, Kaiyang Ji*, and 5 more authorsarXiv preprint arXiv:2508.01651, 20253d object affordance grounding aims to predict the touchable regions on a 3d object, which is crucial for human-object interaction (HOI), embodied perception, and robot learning. Recent advances tackle this problem via learning through demonstration images. However, these methods fail to capture the general affordance knowledge within the image, leading to poor generalization. To address this issue, we propose to use text-to-image diffusion models to extract the general affordance knowledge due to we find such models can generate semantically valid HOI images, which demonstrate that their internal representation space is highly correlated with real-world affordance concepts. Specifically, we introduce the DAG: a diffusion-based 3d affordance grounding framework, which leverages the frozen internal representations of the text-to-image diffusion model and unlocks affordance knowledge within the diffusion model to perform 3D affordance grounding. We further introduce an affordance block and a multi-source affordance decoder to endow 3D dense affordance prediction. Extensive experimental evaluations show that our model excels over well-established methods and exhibits open-world generalization.
@article{wang2025dag, title = {DAG: Unleash the Potential of Diffusion Model for Open-Vocabulary 3D Affordance Grounding}, author = {Wang, Hanqing and Zhang, Zhenhao and Ji, Kaiyang and Liu, Mingyu and Yin, Wenti and Chen, Yuchao and Liu, Zhirui and Zhang, Hangxing}, journal = {arXiv preprint arXiv:2508.01651}, year = {2025}, } - preprint
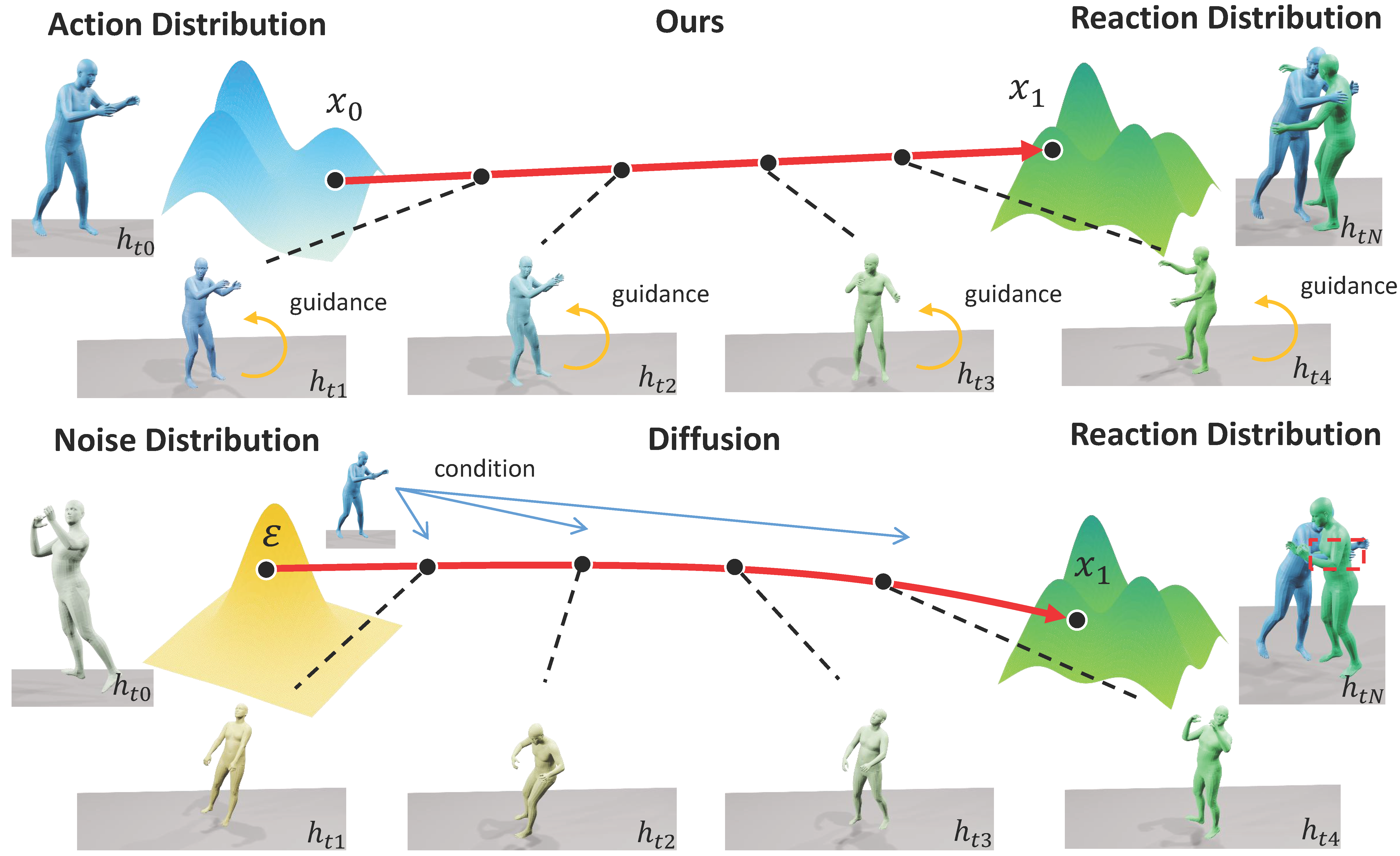 ARFlow: Human Action-Reaction Flow Matching with Physical GuidanceWentao Jiang, Jingya Wang, Kaiyang Ji, and 3 more authorsarXiv preprint arXiv:2503.16973, 2025
ARFlow: Human Action-Reaction Flow Matching with Physical GuidanceWentao Jiang, Jingya Wang, Kaiyang Ji, and 3 more authorsarXiv preprint arXiv:2503.16973, 2025Human action-reaction synthesis, a fundamental challenge in modeling causal human interactions, plays a critical role in applications ranging from virtual reality to social robotics. While diffusion-based models have demonstrated promising performance, they exhibit two key limitations for interaction synthesis: reliance on complex noise-to-reaction generators with intricate conditional mechanisms, and frequent physical violations in generated motions. To address these issues, we propose Action-Reaction Flow Matching (ARFlow), a novel framework that establishes direct action-to-reaction mappings, eliminating the need for complex conditional mechanisms. Our approach introduces a physical guidance mechanism specifically designed for Flow Matching (FM) that effectively prevents body penetration artifacts during sampling. Moreover, we discover the bias of traditional flow matching sampling algorithm and employ a reprojection method to revise the sampling direction of FM. To further enhance the reaction diversity, we incorporate randomness into the sampling process. Extensive experiments on NTU120, Chi3D and InterHuman datasets demonstrate that ARFlow not only outperforms existing methods in terms of Fréchet Inception Distance and motion diversity but also significantly reduces body collisions, as measured by our new Intersection Volume and Intersection Frequency metrics.
@article{jiang2025arflow, title = {ARFlow: Human Action-Reaction Flow Matching with Physical Guidance}, author = {Jiang, Wentao and Wang, Jingya and Ji, Kaiyang and Jia, Baoxiong and Huang, Siyuan and Shi, Ye}, journal = {arXiv preprint arXiv:2503.16973}, year = {2025}, } - ICCV 2025 Highlight
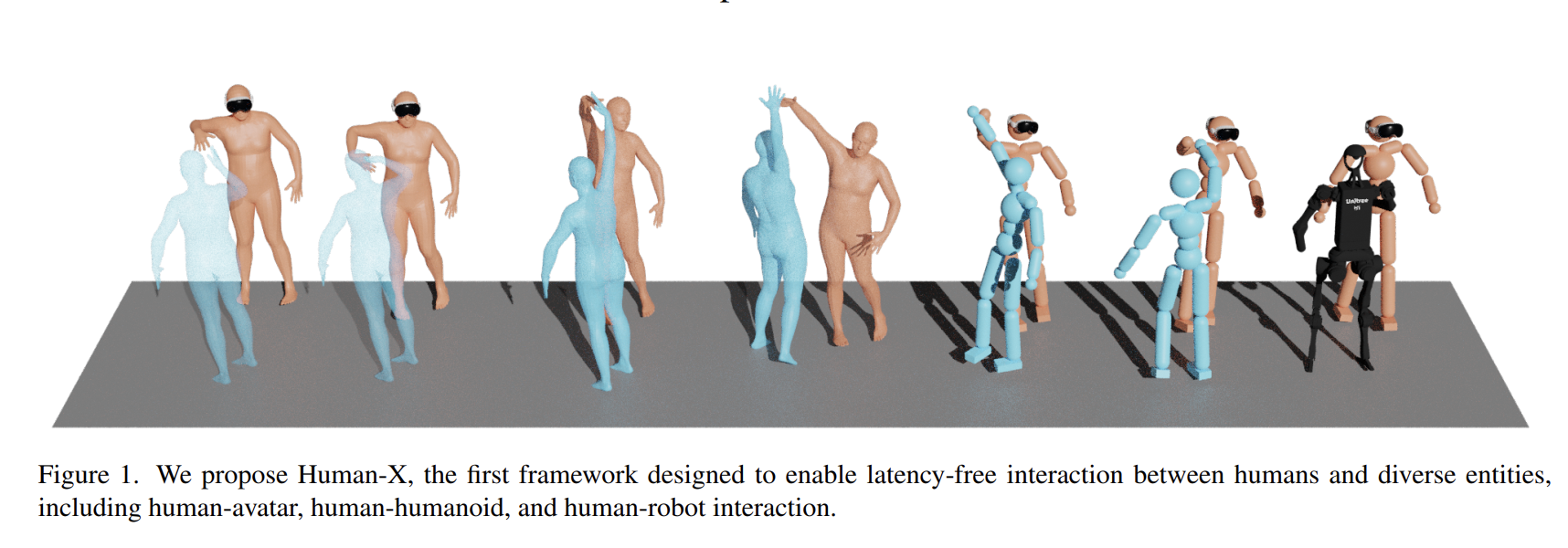 Towards Immersive Human-X Interaction: A Real-Time Framework for Physically Plausible Motion SynthesisKaiyang Ji, Ye Shi, Zichen Jin, and 5 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
Towards Immersive Human-X Interaction: A Real-Time Framework for Physically Plausible Motion SynthesisKaiyang Ji, Ye Shi, Zichen Jin, and 5 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025Real-time synthesis of physically plausible human interactions remains a critical challenge for immersive VR/AR systems and humanoid robotics. While existing methods demonstrate progress in kinematic motion generation, they often fail to address the fundamental tension between real-time responsiveness, physical feasibility, and safety requirements in dynamic human-machine interactions. We introduce Human-X, a novel framework designed to enable immersive and physically plausible human interactions across diverse entities, including human-avatar, human-humanoid, and human-robot systems. Unlike existing approaches that focus on post-hoc alignment or simplified physics, our method jointly predicts actions and reactions in real-time using an auto-regressive reaction diffusion planner, ensuring seamless synchronization and context-aware responses. To enhance physical realism and safety, we integrate an actor-aware motion tracking policy trained with reinforcement learning, which dynamically adapts to interaction partners’ movements while avoiding artifacts like foot sliding and penetration. Extensive experiments on the Inter-X and InterHuman datasets demonstrate significant improvements in motion quality, interaction continuity, and physical plausibility over state-of-the-art methods. Our framework is validated in real-world applications, including virtual reality interface for human-robot interaction, showcasing its potential for advancing human-robot collaboration.
@inproceedings{ji2025towards, title = {Towards Immersive Human-X Interaction: A Real-Time Framework for Physically Plausible Motion Synthesis}, author = {Ji, Kaiyang and Shi, Ye and Jin, Zichen and Chen, Kangyi and Xu, Lan and Ma, Yuexin and Yu, Jingyi and Wang, Jingya}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, pages = {10173--10183}, year = {2025}, }
2024
- CVPR 2024
 A unified diffusion framework for scene-aware human motion estimation from sparse signalsJiangnan Tang, Jingya Wang, Kaiyang Ji, and 3 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
A unified diffusion framework for scene-aware human motion estimation from sparse signalsJiangnan Tang, Jingya Wang, Kaiyang Ji, and 3 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024Estimating full-body human motion via sparse tracking signals from head-mounted displays and hand controllers in 3D scenes is crucial to applications in AR/VR. One of the biggest challenges to this task is the one-to-many mapping from sparse observations to dense full-body motions, which endowed inherent ambiguities. To help resolve this ambiguous problem, we introduce a new framework to combine rich contextual information provided by scenes to benefit fullbody motion tracking from sparse observations. To estimate plausible human motions given sparse tracking signals and 3D scenes, we develop S2Fusion, a unified framework fusing Scene and sparse Signals with a conditional difFusion model. S2Fusion first extracts the spatial-temporal relations residing in the sparse signals via a periodic autoencoder, and then produces time-alignment feature embedding as additional inputs. Subsequently, by drawing initial noisy motion from a pre-trained prior, S2Fusion utilizes conditional diffusion to fuse scene geometry and sparse tracking signals to generate full-body scene-aware motions. The sampling procedure of S2Fusion is further guided by a specially designed scene-penetration loss and phase-matching loss, which effectively regularizes the motion of the lower body even in the absence of any tracking signals, making the generated motion much more plausible and coherent. Extensive experimental results have demonstrated that our S2Fusion outperforms the state-of-the-art in terms of estimation quality and smoothness.
@inproceedings{tang2024unified, title = {A unified diffusion framework for scene-aware human motion estimation from sparse signals}, author = {Tang, Jiangnan and Wang, Jingya and Ji, Kaiyang and Xu, Lan and Yu, Jingyi and Shi, Ye}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {21251--21262}, year = {2024}, }